
Page 31 -
P. 31
그런데 여러분도 알고 있겠지만 시청률 조사와 동전 던지기 이야기는 수학으로서는 같은 이야
기입니다. 시청률 조사에서 진정한 분포는 P(X i 5 ◯) 5 0.2, P(X i 5 3) 5 0.8이었습니다
(i 5 1, … , 50).
이 이야기에서 전하고 싶었던 것은 ‘현실의 관측값의 배후에 진정한 분포가 있다고 가정하고 그
것을 맞히는 것을 목표로 한다’는 사고방식입니다.
6
기댓값의 추정 추정 및 검정
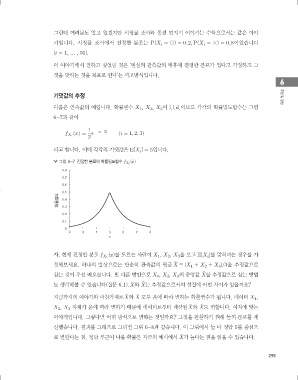
다음은 연속값의 예입니다. 확률변수 X 1 , X 2 , X 3 이 i.i.d.이므로 각각의 확률밀도함수는 그림
6-7과 같이
]
라고 합니다. 이때 각각의 기댓값은 E[X i 5 5입니다.
(x)
그림 6-7 진정한 분포의 확률밀도함수 f X i
0.8
0.7
0.6
0.5
확률밀도 0.4
0.3
0.2
0.1
0
2 3 4 5 6 7 8
x
(x)를 모르는 사람이 X 1 , X 2 , X 3 ]를 맞히려는 경우를 가
자, 현재 진정한 분포 f Xi 을 보고 E[X i
¯
정해보세요. 하나의 발상으로는 단순히 관측값의 평균 X ≡ (X 1 1 X 2 1 X 3 )/3을 추정값으로
̃
삼는 것이 우선 떠오릅니다. 또 다른 방안으로 X 1 , X 2 , X 3 의 중앙값 X를 추정값으로 삼는 방법
¯
̃
도 생각해볼 수 있습니다(질문 6.1). X와 X는 추정값으로서의 성질에 어떤 차이가 있을까요?
¯ ̃
지금까지의 이야기와 마찬가지로 X와 X 모두 운에 따라 변하는 확률변수가 됩니다. 데이터 X 1 ,
¯
̃
X 2 , X 3 자체가 운에 따라 변하기 때문에 데이터로부터 계산된 X와 X도 변합니다. 이치에 맞는
이야기입니다. 그렇다면 어떤 방식으로 변하는 것일까요? 그것을 관찰하기 위해 둘의 분포를 계
산했습니다. 결과를 그래프로 그리면 그림 6-8과 같습니다. 이 그림에서 둘 다 정답 5를 중심으
로 변한다는 점, 정답 부근이 나올 확률은 지금의 예시에서 X가 높다는 점을 읽을 수 있습니다.
̃
295
06 프로그래머를 위한 확률통계.indd 295 2019. 4. 25. 오전 11:41