
Page 17 - 006975
P. 17
으로는 쉽게 해결될 수 있습니다. 예를 들어 ‘이미지에 있는 모든 빨간색 픽셀을 선택’하는 문제는
RGB 포맷에서는 쉽습니다. 반면에 ‘이미지의 채도를 낮추는’ 것은 HSV 포맷이 더 쉽습니다. 머
신 러닝 모델은 입력 데이터에서 적절한 표현을 찾는 것입니다. 이런 데이터 변환은 분류 작업 같
은 문제를 더 쉽게 해결할 수 있도록 만들어 줍니다.
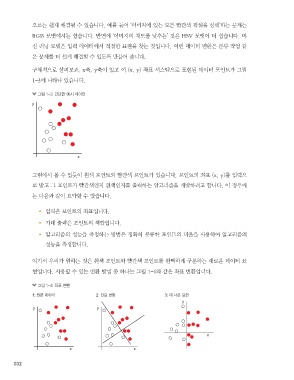
구체적으로 살펴보죠. x축, y축이 있고 이 (x, y) 좌표 시스템으로 표현된 데이터 포인트가 그림
1-3에 나타나 있습니다.
그림 1-3 간단한 예시 데이터
y
x
그림에서 볼 수 있듯이 흰색 포인트와 빨간색 포인트가 있습니다. 포인트의 좌표 (x, y)를 입력으
로 받고 그 포인트가 빨간색인지 흰색인지를 출력하는 알고리즘을 개발하려고 합니다. 이 경우에
는 다음과 같이 요약할 수 있습니다.
● 입력은 포인트의 좌표입니다.
● 기대 출력은 포인트의 색깔입니다.
● 알고리즘의 성능을 측정하는 방법은 정확히 분류한 포인트의 비율을 사용하여 알고리즘의
성능을 측정합니다.
여기서 우리가 원하는 것은 흰색 포인트와 빨간색 포인트를 완벽하게 구분하는 새로운 데이터 표
현입니다. 사용할 수 있는 변환 방법 중 하나는 그림 1-4와 같은 좌표 변환입니다.
그림 1-4 좌표 변환
1: ਗࠄ ؘఠ 2: ઝ ߸ജ 3: ؊ ա അ
y
y y
x
x x
032
deeplearning_07.indd 32 2018-10-05 오전 9:08:59