
Page 25 -
P. 25
1
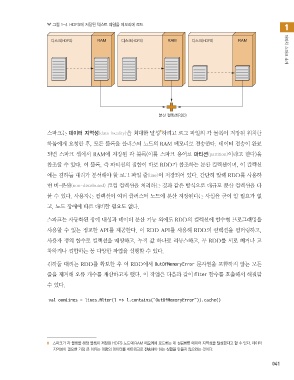
그림 1-4 HDFS에 저장된 텍스트 파일을 메모리에 로드
٣झ )%'4 RAM ٣झ )%'4 RAM ٣झ )%'4 RAM 아파치 스파크 소개
࠙ ஸ۩࣌ 3%%
8
스파크는 데이터 지역성(data locality)을 최대한 달성 하려고 로그 파일의 각 블록이 저장된 위치를
하둡에게 요청한 후, 모든 블록을 클러스터 노드의 RAM 메모리로 전송한다. 데이터 전송이 완료
되면 스파크 셸에서 RAM에 저장된 각 블록(이를 스파크 용어로 파티션(partition)이라고 한다)을
참조할 수 있다. 이 블록, 즉 파티션의 집합이 바로 RDD가 참조하는 분산 컬렉션이며, 이 컬렉션
에는 김하둡 대리가 분석해야 할 로그 파일 줄(line)이 저장되어 있다. 간단히 말해 RDD를 사용하
면 비-분산(non-distributed) 로컬 컬렉션을 처리하는 것과 같은 방식으로 대규모 분산 컬렉션을 다
룰 수 있다. 사용자는 컬렉션이 여러 클러스터 노드에 분산 저장된다는 사실을 굳이 알 필요가 없
고, 노드 장애에 따로 대비할 필요도 없다.
스파크는 자동화된 장애 내성과 데이터 분산 기능 외에도 RDD의 컬렉션에 함수형 프로그래밍을
사용할 수 있는 정교한 API를 제공한다. 이 RDD API를 사용해 RDD의 컬렉션을 필터링하고,
사용자 정의 함수로 컬렉션을 매핑하고, 누적 값 하나로 리듀스하고, 두 RDD를 서로 빼거나 교
차하거나 결합하는 등 다양한 작업을 실행할 수 있다.
김하둡 대리는 RDD를 확보한 후 이 RDD에서 OutOfMemoryError 문자열을 포함하지 않는 모든
줄을 제거해 오류 개수를 계산하고자 했다. 이 작업은 다음과 같이 filter 함수를 호출해서 해결할
수 있다.
val oomLines = lines.filter(l => l.contains("OutOfMemoryError")).cache()
8 스파크가 각 블록을 해당 블록이 저장된 HDFS 노드의 RAM 메모리에 로드하는 데 성공하면 데이터 지역성을 달성했다고 할 수 있다. 데이터
지역성이 필요한 가장 큰 이유는 대량의 데이터를 네트워크로 전송해야 하는 상황을 만들지 않으려는 것이다.
041
spark_08.indd 41 2018-05-08 오후 6:26:12