
Page 24 -
P. 24
1.3 스파크 프로그램의 실행 과정 S p A r k
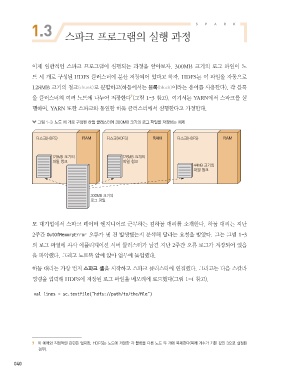
이제 일반적인 스파크 프로그램이 실행되는 과정을 알아보자. 300MB 크기의 로그 파일이 노
드 세 개로 구성된 HDFS 클러스터에 분산 저장되어 있다고 하자. HDFS는 이 파일을 자동으로
128MB 크기의 청크(chunk)로 분할하고(하둡에서는 블록(block)이라는 용어를 사용한다), 각 블록
7
을 클러스터의 여러 노드에 나누어 저장한다 (그림 1-3 참고). 여기서는 YARN에서 스파크를 실
행하며, YARN 또한 스파크와 동일한 하둡 클러스터에서 실행한다고 가정한다.
그림 1-3 노드 세 개로 구성된 하둡 클러스터에 300MB 크기의 로그 파일을 저장하는 예제
٣झ )%'4 RAM ٣झ )%'4 RAM ٣झ )%'4 RAM
.# ӝ .# ӝ
ੌ ੌ
.# ӝ
ੌ
.# ӝ
۽Ӓ ੌ
모 대기업에서 스파크 데이터 엔지니어로 근무하는 김하둡 대리를 소개한다. 하둡 대리는 지난
2주간 OutOfMemoryError 오류가 몇 건 발생했는지 분석해 달라는 요청을 받았다. 그는 그림 1-3
의 로그 파일에 자사 애플리케이션 서버 클러스터가 남긴 지난 2주간 오류 로그가 저장되어 있음
을 파악했다. 그리고 노트북 앞에 앉아 업무에 돌입했다.
하둡 대리는 가장 먼저 스파크 셸을 시작하고 스파크 클러스터에 연결했다. 그러고는 다음 스칼라
명령을 입력해 HDFS에 저장된 로그 파일을 메모리에 로드했다(그림 1-4 참고).
val lines = sc.textFile("hdfs://path/to/the/file")
7 이 예제와 직접적인 관련은 없지만, HDFS는 노드에 저장한 각 블록을 다른 노드 두 개에 복제한다(복제 계수가 기본 값인 3으로 설정된
경우).
040
spark_08.indd 40 2018-05-08 오후 6:26:11