
Page 24 -
P. 24
이렇게 가능도가 가장 커지는 매개변수를 찾는 추정 방법을 최대가능도 추정(maximum likelihood
estimation)이라 부르고, 추정 결과로 정해진 매개변수 값을 최대가능도 추정 값(maximum likelihood
estimate)이라고 한다. 추정된 매개변수 값은 한 점(점 추정)임을 기억해 두자.
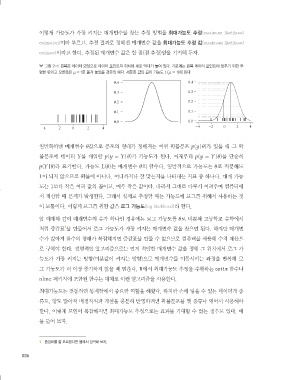
그림 2-1 왼쪽은 데이터 모양으로 데이터 포인트의 위치에 세로 막대가 놓여 있다. 가운데는 왼쪽 데이터 포인트에 맞추기 위한 투
명한 판이고 오른쪽은 μ = 1로 옮겨 놓았을 경우의 예다. 세로축 값의 곱이 가능도 L(μ 5 1)이 된다
일반화하면 매개변수 θ값으로 분포의 형태가 정해지는 어떤 확률분포 p(у|θ)가 있을 때 그 확
률분포에 데이터 Y를 대입한 p(у 5 Y|θ)가 가능도가 된다. 이제부터 p(у 5 Y|θ)를 단순히
p(Y|θ)라 표기한다. 가능도 L(θ)는 매개변수 θ의 함수다. 일반적으로 가능도는 θ로 적분해도
1이 되지 않으므로 확률이 아니다. 어디까지나 잘 맞는지를 나타내는 지표 중 하나다. 대개 가능
도는 1보다 작은 여러 값의 곱이고, 매우 작은 값이다. 따라서 그대로 다루기 어려우며 컴퓨터에
서 계산할 때 문제가 발생한다. 그래서 실제로 추정할 때는 가능도에 로그를 취해서 사용하는 것
이 보통이다. 이렇게 로그를 취한 값을 로그 가능도(log likelihood)라 한다.
앞 예제와 같이 매개변수의 수가 하나인 경우에는 로그 가능도를 θ로 미분해 고등학교 수학에서
1
처럼 증감표 를 만들어서 로그 가능도가 가장 커지는 매개변수 값을 찾으면 된다. 하지만 매개변
수가 많아져 함수의 형태가 복잡해지면 증감표를 만들 수 없으므로 컴퓨터를 사용해 수치 계산으
로 구해야 한다. 전형적인 알고리즘으로는 먼저 적당한 매개변수 값을 정해 그 위치에서 로그 가
능도가 가장 커지는 방향(미분값이 커지는 방향)으로 매개변수를 이동시키는 과정을 반복해 로
그 가능도가 더 이상 증가하지 않을 때 멈춘다. R에서 최대가능도 추정을 수행하는 optim 함수나
nlme 패키지에 포함된 함수는 대체로 이런 알고리즘을 사용한다.
최대가능도는 전통적인 통계학에서 중요한 역할을 해왔다. 하지만 손에 넣을 수 있는 데이터가 종
류도, 양도 많아져 배경지식과 가설을 충분히 반영하려면 확률분포를 몇 종류나 엮어서 사용해야
한다. 이렇게 모델이 복잡해지면 최대가능도 추정으로는 효과를 기대할 수 없는 경우도 있다. 예
를 들어 보자.
1 증감표를 잘 모르겠다면 웹에서 검색해 보자.
036
1데이터분석을위한베이지안통계모델링.indd 36 2019. 3. 14. 오후 8:32