
Page 29 -
P. 29
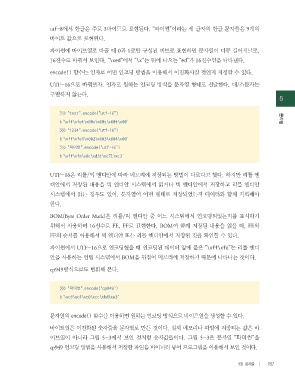
utf-8에서 한글은 주로 3바이트로 표현된다. “파이썬”이라는 세 글자의 한글 문자들은 9개의
바이트 값으로 표현된다.
파이썬에 바이트열로 바꿀 때 0과 1로만 구성된 비트로 표현하면 문자열이 너무 길어지므로,
16진수로 바꿔서 보인다. “\xed”에서 “\x”는 뒤에 나오는 “ed”가 16진수임을 나타낸다.
encode() 함수는 인자로 어떤 인코딩 방법을 이용해서 이진화시킬 것인지 지정할 수 있다.
UTF-16으로 바꿔보자. 인자로 원하는 인코딩 방식을 문자열 형태로 전달한다. 대/소문자는
구별하지 않는다.
5
>>> "test".encode("utf-16")
b'\xff\xfet\x00e\x00s\x00t\x00' 문자열
>>> "1234".encode("utf-16")
b'\xff\xfe1\x002\x003\x004\x00'
>>> "파이썬".encode("utf-16")
b'\xff\xfe\x0c\xd3t\xc7l\xc3'
UTF-16은 리틀/빅 엔디안에 따라 메모리에 저장되는 방법이 다르다고 했다. 하지만 리틀 엔
디안에서 저장된 내용을 빅 엔디안 시스템에서 읽거나 빅 엔디안에서 저장하고 리틀 엔디안
시스템에서 읽는 경우도 있어, 문자열이 어떤 형태로 저장되었는지 데이터와 함께 기록해야
한다.
BOM(Byte Order Mark)은 리틀/빅 엔디안 중 어느 시스템에서 인코딩되었는지를 표시하기
위해서 사용하며 16진수로 FE, FF로 표현한다. BOM이 함께 저장된 내용을 읽을 때, FE와
FF의 순서를 이용해서 빅 엔디안 또는 리틀 엔디안에서 저장된 것을 확인할 수 있다.
파이썬에서 UTF-16으로 인코딩했을 때 인코딩된 데이터 앞에 붙은 “\xff\xfe”는 리틀 엔디
안을 사용하는 인텔 시스템에서 BOM을 뒤집어 메모리에 저장하기 때문에 나타나는 것이다.
cp949방식으로도 변환해 본다.
>>> "파이썬".encode("cp949")
b'\xc6\xc4\xc0\xcc\xbd\xe3'
문자열의 encode() 함수를 이용하면 원하는 인코딩 방식으로 바이트열을 생성할 수 있다.
바이트열은 이진화된 숫자들을 문자열로 만든 것이다. 실제 메모리나 파일에 저장되는 값은 바
이트열이 아니라 그림 5-3에서 보인 것처럼 숫자값들이다. 그림 5-3은 문자열 “파이썬”을
cp949 인코딩 방법을 사용해서 저장한 파일을 바이너리 뷰어 프로그램을 이용해서 보인 것이다.
5장 문자열 │ 187