
Page 24 -
P. 24
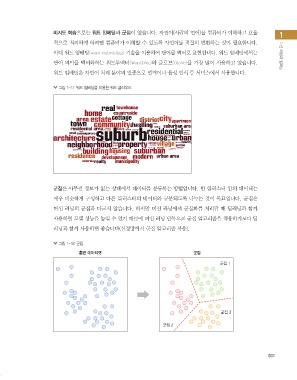
비지도 학습으로는 워드 임베딩과 군집이 있습니다. 자연어(사람의 언어)를 컴퓨터가 이해하고 효율 1
적으로 처리하게 하려면 컴퓨터가 이해할 수 있도록 자연어를 적절히 변환하는 것이 필요합니다.
이때 워드 임베딩(word embedding) 기술을 이용하여 단어를 벡터로 표현합니다. 워드 임베딩에서는 머신 러닝과 딥러닝
단어 의미를 벡터화하는 워드투벡터(Word2Vec)와 글로브(GloVe)를 가장 많이 사용하고 있습니다.
워드 임베딩은 자연어 처리 분야의 일종으로 번역이나 음성 인식 등 서비스에서 사용합니다.
그림 1-17 워드 임베딩을 이용한 워드 클라우드
군집은 아무런 정보가 없는 상태에서 데이터를 분류하는 방법입니다. 한 클러스터 안의 데이터는
매우 비슷하게 구성하고 다른 클러스터의 데이터와 구분되도록 나누는 것이 목표입니다. 군집은
머신 러닝의 군집과 다르지 않습니다. 하지만 머신 러닝에서 군집화를 처리할 때 딥러닝과 함께
사용하면 모델 성능을 높일 수 있기 때문에 머신 러닝 단독으로 군집 알고리즘을 적용하기보다 딥
러닝과 함께 사용하면 좋습니다(신경망에서 군집 알고리즘 사용).
그림 1-18 군집
ള۲ ؘఠࣇ ҵ
ҵ
ҵ
ҵ
031